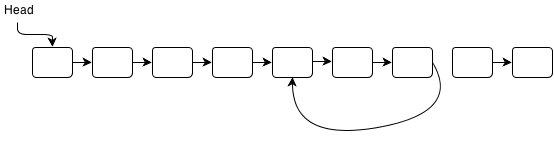
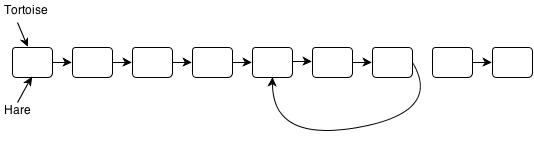
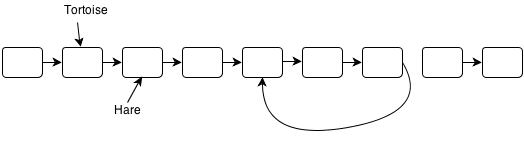
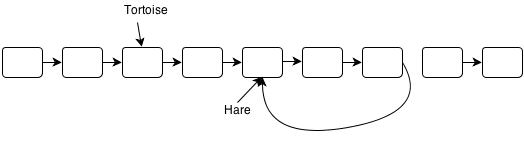
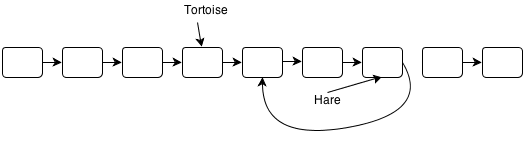
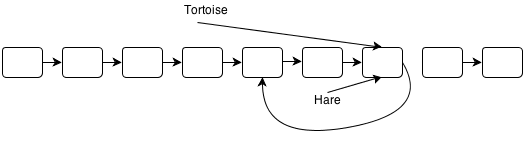
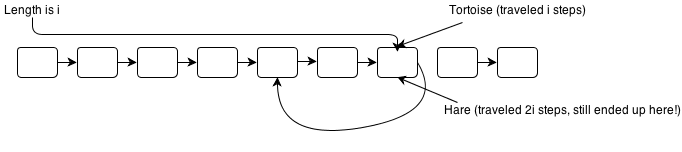
I’ve hosted my solutions for the Ruby Koans on GitHub here:
https://github.com/skunkworks/ruby-koans
I’ve kept up a verbose commentary within the koans code files — each novel insight receives a comment, and every question posed receives a detailed answer.
My approach has been to honor the intentions of its creators by reflecting on deeper insights into Ruby. Lots of googling, lots of reading, lots of pulling up irb to experiment. On more than a few occasions, a novel concept or a “why” question has caused me to get sidetracked for an hour or more just trying to learn more about the mechanics of Ruby
Needless to say, the koans have been really, really fun.